
Storing Information in DNA Archives
Shakespeare's sonnets to Martin Luther King's speech and other files archived in the structure of DNA.


The computing memory required to store ongoing data in biomedicine is now estimated to exceed the computing challenges of running YouTube and Twitter.
Data storing technology has constantly evolved to keep up with advancing human knowledge and scientists are now pioneering next-generation efforts for the future of archive technology:
In response to ongoing demands for massive data repositories in genomics (study of genes) alone, researchers have shown possibility of creating DNA-based archives for large-scale, long-term information deposition. This unusual technique has its origins in the serendipitous findings of intact mammoth and horse genomes decoded from bone, almost 60,000 to 700,000 years after its accidental preservation - to indicate a measure of just how long-term.
The current global data crunch reiterates the need for an alternative repository - with storage capacities set to reach 44 trillion Gigabytes by 2020 and exceed the supply of microchip-grade silicon by 2040. As a memory material, DNA ideally stores information of life for life, is able to pack information densely and enable data retrieval. The quaternary code of DNA written with an alphabet of four nucleotides: cytosine (C), thymine (T), adenine (A) and guanine (G) can be utilized for programmable genetic engineering with a storage density that exceeds electronic memory.
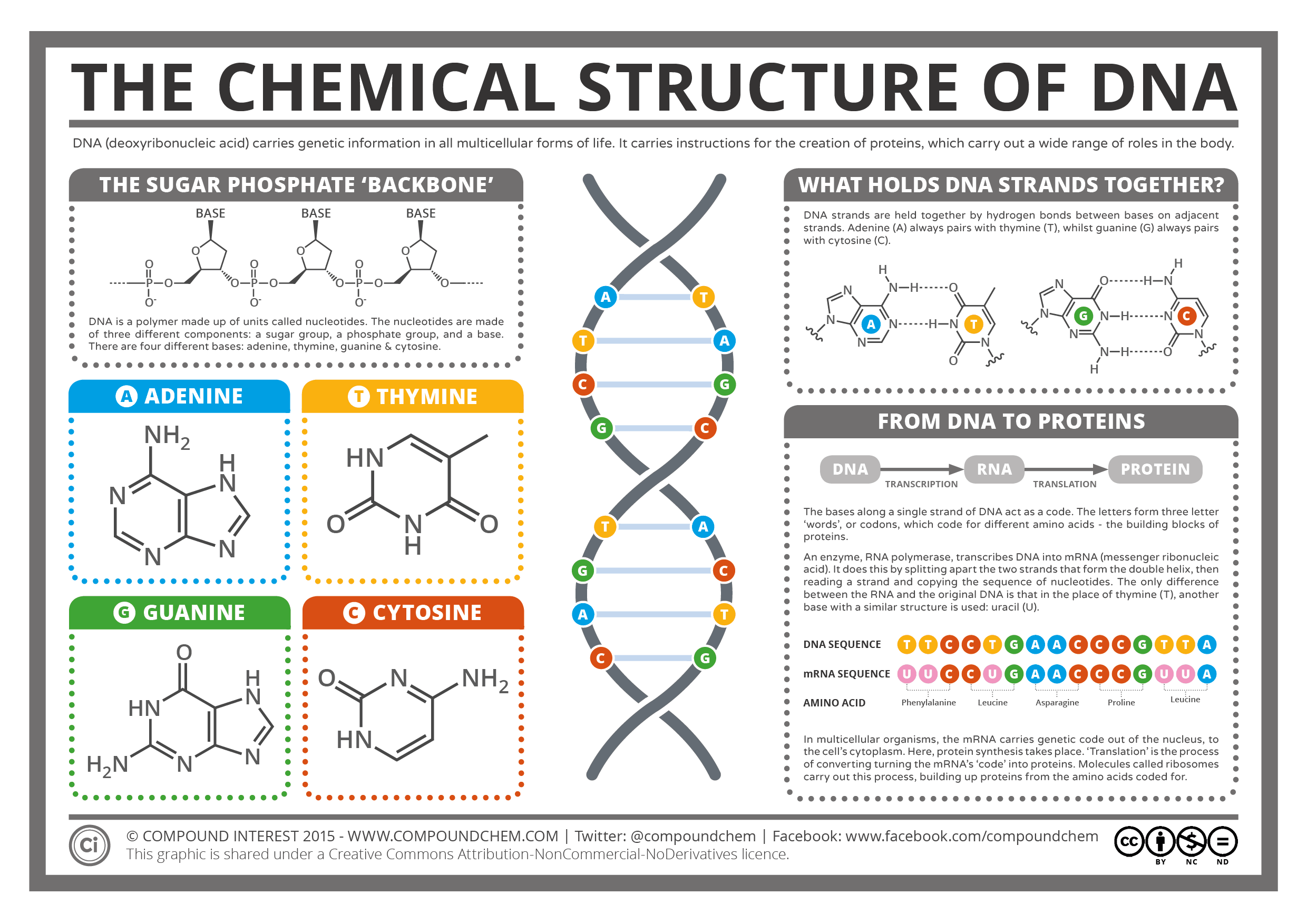
Architecture of DNA and Comparative Storage

The DNA double helix and the storage limits of silicon vs. DNA (via compound chem and Nature News Feature 2016)
Architecturally, four nucleotide bases of DNA form complementary base pairs to self-assemble a double helix. In theory, 2 bits of data can be stored per nucleotide with observed half-life over 500 years. Comparative storage capacities indicate genomic density within a bacteria is equivalent to a storage capacity of ~10^19 bits per cubic centimeter; if this capacity were transferred to a realistic information storage system, the projected global storage needs of ~10^22 bits would be met by just ~1 kg of DNA. Of course achieving that potential isn’t easy, so ongoing research in DNA-based architecture of archival systems has formed a new field, with key contributions made to its advancement.
The method was first demonstrated in 1988 by artist Joe Davis and Harvard researchers, when the team encoded an artificial DNA sequence with an ancient Germanic rune representing life and the female earth named Microvenus. The 2D image of interest was first mathematically converted to a 35-bit binary code, DNA bases assigned to a specific pattern translating bits to nucleotides and a DNA sequence synthesized. The sequence was stored in Escherichia coli bacteria for multiplication and decoded to reconstruct the image, as detailed in the Art Journal :
Recap Method 1: DNA-Based Information Storage

The bigger picture: schematic diagram detailing the underlying method of information storage in DNA (via Art Journal and Sciam blog)
Subsequent storage systems included the key cyclical steps outlined, with methods optimized as technology advanced. Bacteria assisted multiplication for instance was replaced with in-lab instrumentation such as polymerase chain reaction (PCR), to multiply synthetic DNA. Also, synthesize = DNA writing process and sequence = DNA reading.
The small scale of work (35-bits) stemmed from the difficulty of writing and decoding long perfect DNA sequences. In 2011, George Church, a molecular geneticist at Harvard Medical School, began DNA data storage experiments based on this concept, but used a novel encoding scheme that stored a larger scale, html draft of the entire book Regenesis into DNA. In total, the content for storage was a 5.27-megabit stream encoded into DNA and amplified via the polymerase chain reaction to enable reading:
Soon after, Nick Goldman of the European Bioinformatics Institute (EBI) encoded 5.2 million bits of information into DNA, roughly the same amount as Church’s team, albeit via a more complex method for higher density storage. The 5 files of conventional format encoded include:- All of Shakespeare’s sonnets
- An audio clip of Martin Luther King’s ‘I have a dream’ speech
- A classic scientific paper on the structure of DNA published in Nature in 1953
- A photo of the research institute in which this work was done (EBI)
- A file of the code used to enable the complex process
Recap Method: Goldman Encoding

Five files stored in DNA are on the left and the method followed is on the right (via Nature News 2016)
The Microsoft-UoW team initially stored three images at 151 kB, including the Sydney Opera House, a cat and a monkey emoji, which were decoded without mistakes:
Demonstrating New Protocol - Test Images Stored

Three files totaling 151 kB stored via optimized method by Microsoft-UoW team (via UoW publication)
The larger 200 MB archive created by the same team reportedly includes 1) a video bythe band OK Go! 2) Universal Declaration of Human Rights in 100 languages, 3) the top 100 books of Project Gutenberg and 4) a seed database.
At this point, if a user wished to read a single file of the DNA-based archive the entire system had to be decoded. Computer scientist Olgica Milenkovic at the University of Illinois developed a new method that enabled random-access to the preferred data in storage and also enabled re-writing of stored information. As proof-of-concept, they encoded Wiki pages of 6 Universities into DNA and selectively edited context of 3 schools.
The main barrier to commercialization of this process is its extremely high cost, largely due to the DNA writing process (synthesis) than the reading process (sequencing). It costs less to “read” the genome since completion of the Human Genome Project (HGP) in 2003. Some improvements in cost reduction may similarly result from the Human Genome write project (HGP-write), launched by Church and others with the aim of reducing costs by more than 1000-fold within the next 10 years.
The most recent developments in the field were in March 2017, when scientists at the Columbia University and New York Genome Center developed a DNA archive via a new coding strategy named DNA fountain.
The archive consisted of 1) a full computer operating system, 2) an 1895 French film “Arrival of a train at La Ciotat”, 3) an Amazon gift card of $50, 4) a computer virus, 5) a pioneer plaque and 6) a 1948 study by information theorist Claude Shannon.
This archive has the highest storage capacity reported so far at 215 petabytes (PB), 100x the magnitude of storage density reported by previous research teams. This storage system can be copied an unlimited number of times for virtually unlimited data retrieval. Computer scientist Yaniv Erlich recaps the newest advancement in conclusion:
This article is primarily based on a report by George M. Church, Yuan Gao and Sriram Kosuri published in Science Magazine September 2012, available via | doi 10.1126/science.1226355
About the Creator
Thamarasee Jeewandara
scientist/science writer [@Jeew333T]
Keep reading
More stories from Thamarasee Jeewandara and writers in Futurism and other communities.




{kind=link}
{kind=link}
Comments
There are no comments for this story
Be the first to respond and start the conversation.